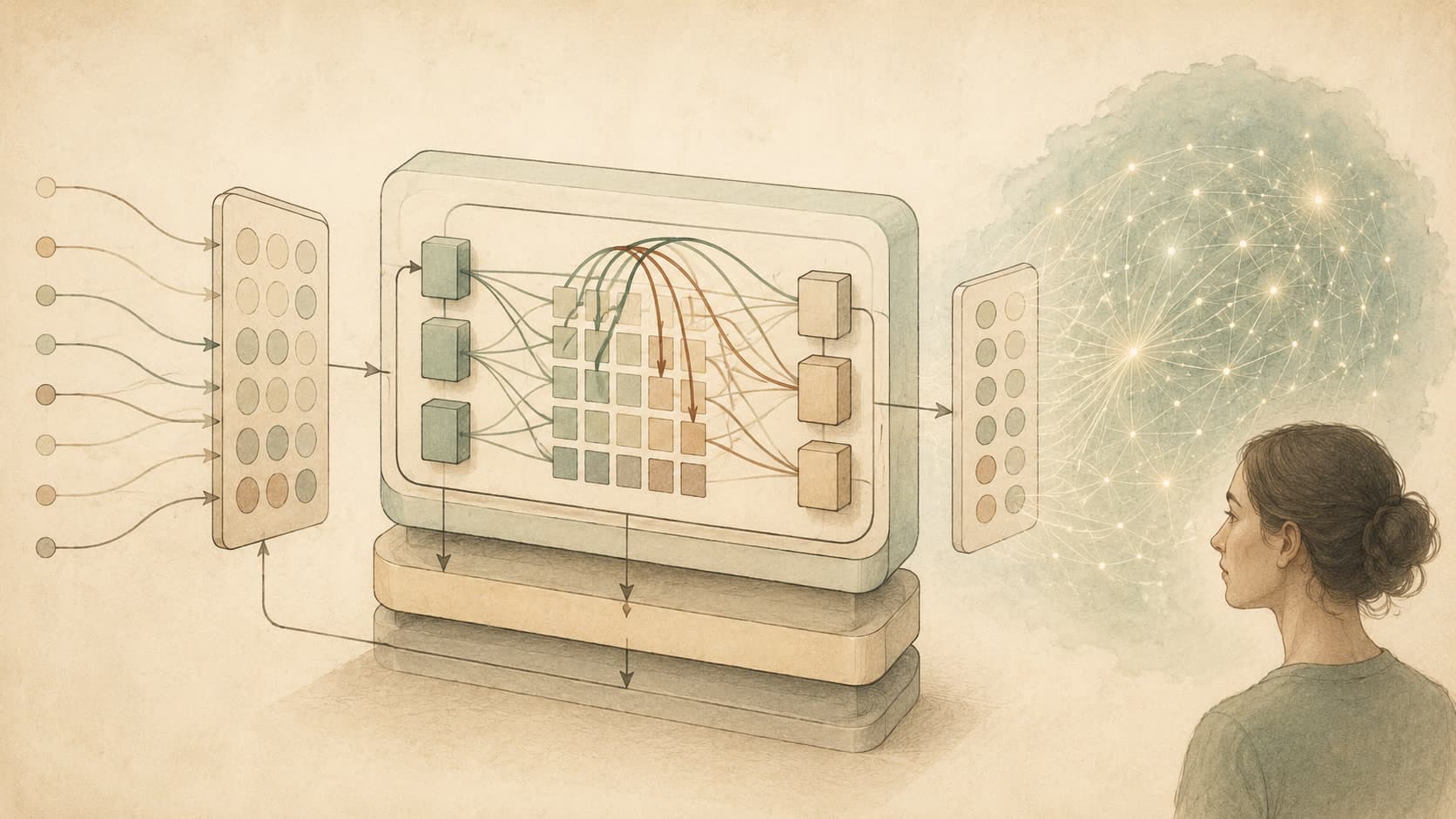
The transformer replaced sequence models that read left to right with one that reads all at once, weighing each token against every other. It is the architectural premise on which most current language and vision models rest.
In plain language
In AI and machine learning, you will run into this term whenever someone talks about how a model is built or used. The transformer replaced sequence models that read left to right with one that reads all at once, weighing each token against every other. It is the architectural premise on which most current language and vision models rest. If you are new to the field, the simplest mental model is this: the attention-based architecture behind modern llms. Read it once with that frame in mind, then come back and read it again — that is usually enough for the rest of the entry to make sense.
An everyday picture
Think of Transformer less like a thinking person and more like someone who has read an enormous amount and now finishes other people's sentences for a living. They have absorbed the shape of the work; they have not memorised any one page.
Where it shows up
Transformer tends to sit inside products that need to read, write, or recognise without a hard-coded rule — assistants, search, document tools, voice apps. It is rarely the only moving part, but it is often the part the user feels.
A small example
Imagine the scene above. The role Transformer plays is the one its blurb describes — The attention-based architecture behind modern LLMs. When a chatbot in a customer service portal reads a question and returns a draft reply, several of these AI ideas — model, prompt, context — are at work behind the single button you saw.
Common misunderstanding
One line to take with you
Transformer is statistics worn well. Useful for patterns; double-check it for facts.